Short-Term Forecasting of Dockless Bike-Sharing Demand with the Built Environment and Weather

英文题目: Short-Term Forecasting of Dockless Bike-Sharing Demand with the Built Environment and Weather
中文题目: 基于建成环境和天气的无桩共享单车需求短期预测
论文作者: 杨扬,邵鑫,朱宇婷,姚恩建,刘冬梅,赵峰
论文期刊: Journal Of Advanced Transportation
论文网址: https://www.proquest.com/docview/2775463270?pq-origsite=wos&accountid=32743
摘要: 为协助相关运营商调配和调度共享单车,同时为设置电子围栏提供指导,本文提出了一个多因素的时空图卷积网络预测模型(SGCNPM),以提高共享单车需求预测的准确性。我们考虑了时间、建成环境和天气因素,使用多图卷积网络(GCN)模拟建成环境,长短期记忆网络(LSTM)提取时空特征,全连接网络(FCN)模拟天气因素影响。我们构建的SGCNPM可以有效融合GCN、LSTM和FCN,从而建立了一种考虑多种因素影响的预测方法。天津市的案例结果表明,所提出的模型能够很好地提高预测精度。此外,我们还分析了不同时期各种因素对模型预测结果的影响。
1. 引言
在过去的几十年里,随着人们对全球变暖和快速城市化的担忧日益加剧,许多城市都在努力推广共享单车,将其作为一种可行的绿色交通解决方案。共享单车系统的成功实施可以为交通拥堵、能源短缺和人类健康恶化等诸多城市问题提供替代解决方案。以一辆共享单车为例,据估计,在生产、运输和报废的整个生命周期中,它将产生约76公斤的二氧化碳排放。然而,在其使用寿命内,平均骑行距离超过4000公里,估计可减少碳排放约105公斤,足以实现“零排放”。共享单车促进了资源的全面节约和循环利用,以更低的资源投入和更高的运营效率满足人们的绿色出行需求,有助于实现碳达峰和碳中和目标。
无桩共享单车自2014年开始在中国推广,并在过去几年迅速发展,并推广到包括美国和英国在内的海外国家。2022年,中国共享单车数量达到2300万辆,远超停靠式共享单车,成为最重要的共享交通方式之一。Hellobike、Mobike等共享单车服务平台是随着移动互联网的蓬勃发展而出现的新兴技术。平台调度和转移共享单车,以匹配供求。目前,共享单车存在利用率低、周转率低、投放范围有限等问题。根据北京市交通委的报告,北京市共享单车的日均周转率仅为1.1,日均活跃的共享单车仅占报告的共享单车总量的16%,周均活跃的共享单车仅占30%。了解不同空间区域的短期客流需求可以帮助平台和运营商有效解决这一问题。然后,将共享单车投放到潜在出行需求更大的地区,以提高利用率和周转率。
因素的选择是需求预测中最重要的步骤之一。除了时间,天气和建成环境也是重要的因素。天气因素包括气温和天气状况。在气温方面,Heinen等人研究表明,当气温在0 ~ 20℃时,出行需求呈正相关;当气温在20 ~ 30℃之间时,需求达到最高水平。在天气状况方面,Hyland和Hong发现降雨和降雪是最不利的天气条件,它们与共享单车需求之间存在负相关关系。建成环境是指为人类活动提供的人工环境,包括大型城市环境,一般具有多样性(或土地利用类型)、设计(特别是公共交通设计)等特点。在土地利用类型方面,Eren和Uz得出结论,商业区的共享单车需求比住宅区高15倍,公园的共享单车需求比学校和地铁高3-5倍。在公共交通的设计方面,Kabak等人研究发现共享单车可以有效地解决最后一公里连接问题,在火车、公共汽车和地铁等交通枢纽附近,共享单车的需求较高。
虽然很多学者在考虑多种因素的基础上,对无桩共享单车需求的短期预测进行了相关研究,但同时考虑天气和建成环境的影响的研究很少。Sun等人的研究表明,出租车需求与建成环境变量以及天气条件之间存在正相关关系。
本文提出了一种多因素短期预测方法,以提高共享单车需求预测的准确性。本文的贡献概述如下:首先,本文考虑了时间、建成环境和天气因素,利用多图卷积网络(GCN)对建成环境进行建模,利用长短时记忆网络(LSTM)提取时间特征,并利用全连接网络(FCN)对天气影响进行建模。本文构建了一种时空图卷积网络预测模型(SGCNPM),该模型能有效融合GCN、LSTM和FCN,从而建立了一种考虑多因素影响的预测方法。中国天津的实际案例结果表明,该模型能较好地提高预测精度。此外,本文还分析了不同时期各因素对模型预测结果的影响。
本文的其余内容组织如下。第2节首先介绍解释变量。第3节提出本研究的建模框架。第4节对企业共享单车数据进行研究,并比较SGCNPM与其他模型的预测性能。第5节总结研究成果并提出未来的研究方向。
2. 文献综述
关于共享单车需求预测的研究较多。根据研究对象的不同,可将其分为有桩式和无桩式。
针对站点式共享单车,Sathishkumar等人讨论了五种小时租赁需求预测模型,包括线性回归、梯度提升机、支持向量机、提升树和极致梯度提升树。Li等人提出了一种时空记忆网络来预测共享单车的短期使用情况。Sohrabi等人提出了广义极值计数模型,可以预测每个站每小时的到站和离站情况。Reynaud等人提出了一种面板混合广义有序logit模型来估计每小时可提供的自行车数量;该模型包括外生变量模型和站点级模型。Hu等人提出了一套广义加性模型,来描述站点式共享单车日均使用率和土地利用、站点特点和COVID-19等自变量之间的时空关系。Collini等人使用双向长短期记忆(Bi-LSTM)网络预测共享单车站中可用自行车和空闲自行车槽的数量。Mehdizadeh Dastjerdi和Morency首先使用鲁文算法识别自行车共享网络中的6个社区,并利用CNN-LSTM预测每个社区的停车需求。与有桩共享单车不同,无桩共享单车可以被用户停放在任何合适的地方。该特性提高了自行车的可用性和服务覆盖范围,但增加了预测的难度。有桩共享单车预测方法不能直接用于无桩自行车共享系统。
对于无桩共享单车系统,Chang等人利用深度学习算法预测共享单车的数量和位置,采用嵌入注意机制的编码器-解码器架构进一步增强预测能力。Shang等人利用大数据分析了COVID-19对共享单车的用户行为和环境效益的影响,他们利用复杂网络理论中的拓扑指标来分析用户行为模式的转换。Yang等人利用空间统计和基于图的方法,分析了在新地铁线路投入运营的一段时间内,南昌市无桩共享单车的出行行文变化。Ai等人提出了卷积长短期记忆(卷积-LSTM)网络来预测短期分布,解决了无桩共享单车的空间相关性和时间相关性。Li和Shuai提出了一种名为CLTFP的深度学习模型,用于预测不同时间和空间条件下共享单车的出行距离和OD分布。以往的研究在模拟相关性时主要考虑了时间相关性,本文发现建成环境对共享单车的需求预测也很重要。例如,A区和B区相距很远。但是由于两个区域的土地利用类型相似,或者两个区域由城市轨道交通连接,所以两个区域会相互影响,对共享单车的需求可能相似。
考虑到建成环境,Xu等人使用了一个4个月的GPS数据集来重建不同地点的共享单车的时间使用模式,并应用特征分解方法来揭示其隐藏的结构。Li等人应用普通最小二乘(OLS)回归和地理加权回归(GWR)模型,探索建成环境和社会人口特征如何影响共享单车使用率。Dong等人提出了基于兴趣点(POIs)聚类的DestiFlow来预测无桩共享单车的需求。Yan等研究了无桩共享单车在地铁站附近的出行距离分布,为无桩共享单车的服务区提供依据。Li等人利用无桩共享单车服务商摩拜单车(Mobike)的数据,量化短途交通方式,并对出行模式进行综合分析。Li等人提出了一个基于重力模型和贝叶斯规则的框架,从个体层面推断无桩共享单车的出行目的。除了共享单车,很多学者也将短时预测运用到其他领域。Zeng等人基于历史停车数据提出了一种预测可用停车位的DWT-Bi-LSTM模型。Ma等人提出了短期流量预测模型,来提高短期流量预测的准确性。Ziheng等人提出了一种深度学习模型MOS-BiAtten,用于预测北京新冠肺炎期间的打车需求。Zhu等人提出了一种深度学习模型,以实现动态区域出租车需求的准确和稳定预测。
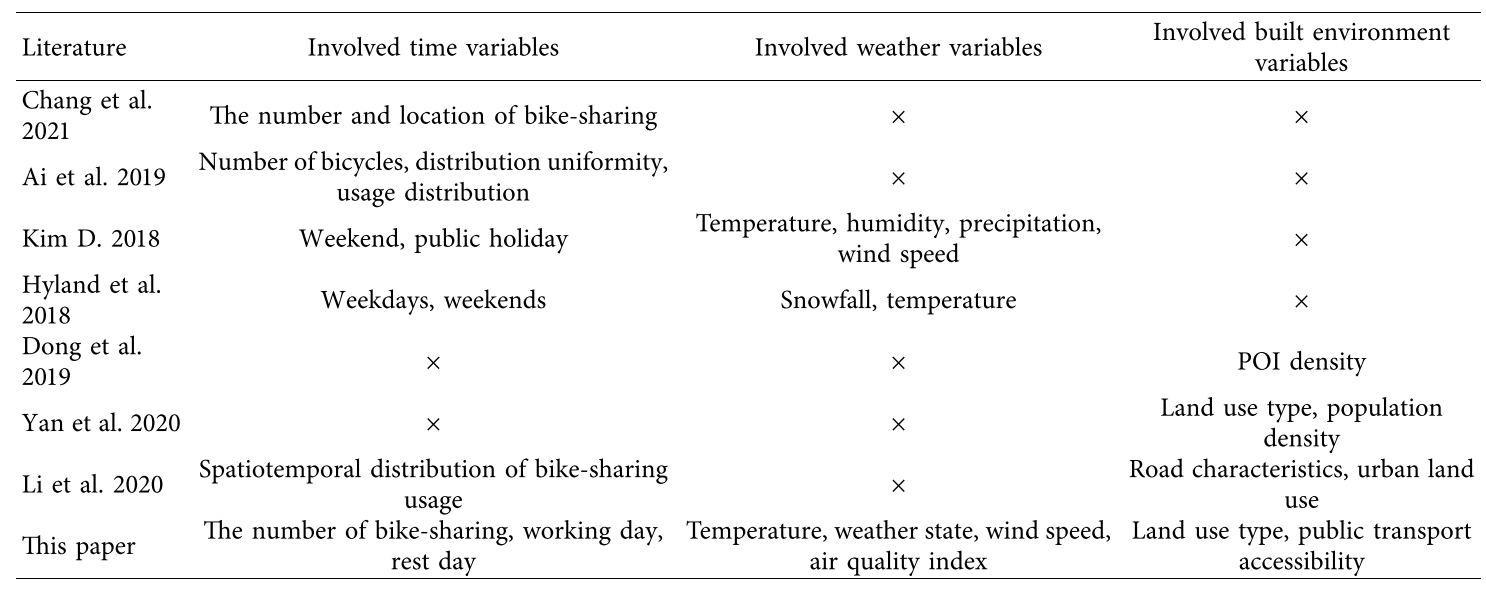
虽然有许多研究分析了需求,也证明了天气和建成环境对需求预测的重要性。然而,很少有研究者将建成环境和天气环境同时作为变量考虑。本文对主要文献中涉及的变量进行了梳理,如表1所示。本文旨在探索建成环境与天气因素共同作用对共享单车需求预测的影响。
表1 关于无桩共享单车的文献中涉及的变量
2.1 前言
共享单车需求短期预测实质上是一个时间序列预测问题。最近的历史需求可以为预测未来的需求提供有价值的信息。本文还考虑了建成环境对短期共享单车需求的影响。在本文中,建成环境的特征是两个因素,土地利用类型和公共交通可达性。
在预测一个地区的需求时,可以直接参考其他具有类似功能的地区。若A区和B区均为居民区,则两个区域共享单车需求的时空特征具有可比性,可在需求预测中相互借鉴。公共交通可达性也是一个重要的时空预测因素。客观地说,地理位置偏远但可到达的区域可以相互关联,这种关联由公共汽车和地铁等公共交通造成。此外,时段、星期和天气条件等属性也会影响短期共享单车需求。本文将研究区域均匀地划分为若干个网格。每个网格代表一个区域,用(m, n)表示,并将一天按照相同的时间间隔划分为不同的时间段。相关变量定义如下:
2.1.1 需求密度
网格(m, n)中第t个时段(h)的需求定义为网格中该时段的需求数量,用![]() 表示。所有
表示。所有![]() 网格在第t个时点的共享单车需求被定义为矩阵
网格在第t个时点的共享单车需求被定义为矩阵![]() (R为实集),其中第(m, n)个元素为
(R为实集),其中第(m, n)个元素为![]()
2.1.2 土地利用类型
用各土地利用类型的数量来衡量该因子。设![]() 表示网格(m, n)中土地利用类型i的数量。土地利用类型i分为9类:地铁站、公园、购物中心、培训机构、办公楼、学校、知名企业、住宅小区、综合餐厅。所有
表示网格(m, n)中土地利用类型i的数量。土地利用类型i分为9类:地铁站、公园、购物中心、培训机构、办公楼、学校、知名企业、住宅小区、综合餐厅。所有![]() 网格中土地利用类型i的数量被定义为矩阵
网格中土地利用类型i的数量被定义为矩阵![]() (R为实集),其中第(m, n)个元素为
(R为实集),其中第(m, n)个元素为![]()
2.1.3 公共交通的可达性
公共交通系统是公共交通可达性的基础。公共交通网络的空间布局、实际运行方案以及系统内公共交通方式与轨道交通的配合,都会影响到旅客在公共交通系统内的出行路径和出行方式的选择,进而影响公共交通的可达性。设![]() 表示网格(m, n)中公共交通的可达性,表示从m区域到n区域的公共交通方式数量。所有
表示网格(m, n)中公共交通的可达性,表示从m区域到n区域的公共交通方式数量。所有![]() 网格中公共交通的可达性被定义为矩阵
网格中公共交通的可达性被定义为矩阵![]() (R为实集),其中(m, n)第n个元素为
(R为实集),其中(m, n)第n个元素为![]()
2.1.4 天数
通过对训练集中时间的需求密度分布进行实证检验,选择了月日、周日和日时。设![]() 表示月中的日,
表示月中的日,![]() 表示周中的日,
表示周中的日,![]() 表示日中的时。此外,引入了一个虚拟变量
表示日中的时。此外,引入了一个虚拟变量![]() ,以区分休息日(包括节假日和周末)和工作日之间的区别,表示为
,以区分休息日(包括节假日和周末)和工作日之间的区别,表示为![]() (0为休息日,1为工作日)。
(0为休息日,1为工作日)。
2.1.5 天气
本文考虑了五类天气变量:天气状态、最高气温、最低气温、风力等级和空气质量指数。设![]() 表示天气状态(0表示多云;1表示晴天;2表示雾天;3表示雪天;4表示雨天)。
表示天气状态(0表示多云;1表示晴天;2表示雾天;3表示雪天;4表示雨天)。![]() 分别表示最高气温、最低气温、风力等级和空气质量指数。天气状态、最高气温、最低气温取一个时间区间的值,风力等级和空气质量取每个时间区间的平均值。
分别表示最高气温、最低气温、风力等级和空气质量指数。天气状态、最高气温、最低气温取一个时间区间的值,风力等级和空气质量取每个时间区间的平均值。
3. 方法论
SGCNPM由两个子模型组成:(1)基于多图卷积网络和LSTM的时空和建成环境变量模型和(2)基于全连通网络的天气变量模型。以不同的权重将两个子模型的输出结果进行融合,得到各区域的共享单车需求,如图1所示。
首先,我们通过多个图对区域之间的关系进行编码,例如距离、POI相似性和公共交通可达性。利用多图卷积网络捕获非欧几里得关系,利用LSTM提取时间特征,输出子模型的预测结果;通过全连通网络输入历史需求和天气标签,输出子模型的预测结果。最后,对两种预测结果进行加权融合,输出预测结果。
在空间层面,利用多图卷积网络对非欧几里德关系进行建模。
在时间层面,考虑共享单车的历史出行特征,采用LSTM模型对共享单车的出行特征进行建模,得到共享单车的需求规律。
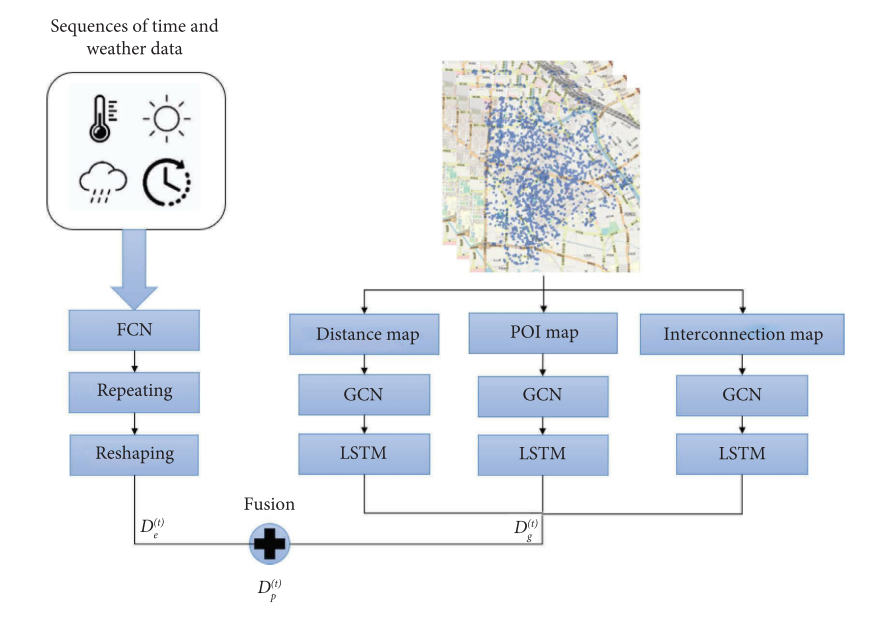
图1 SGCNPM的结构框架
4. 实验与结果
自2017年2月共享单车进入天津以来,该行业的发展经历了四个阶段:早期阶段、发展阶段、繁荣阶段和成熟阶段。最初,天津也存在共享单车过多、乱投放的问题,全市约有 100 万辆共享单车。准确预测共享单车的需求,有助于天津市政府合理投放和调度共享单车,更好地发挥共享单车的绿色出行和慢行交通作用,使天津市在国内企业共享单车管理中保持领先地位。
在本节中,本文首先对数据进行预处理,并用SGCNPM进行共享单车需求预测,然后与其他模型的预测性能进行比较。
4.1 数据收集
本文涉及三种类型的数据收集工作:时空变量、建成环境变量和天气变量。
4.1.1 时空变量
本文使用的数据集来自国内最大的两家共享单车服务平台Hellobike和Mobike,时间跨度为两个月,从2019年5月1日到2019年6月30日。如图2所示,研究地点位于和平区,被黑实线包围。将数据集以1小时为时间间隔进行划分,将研究区域按500m×500m网格划分为53个区域;本文还研究了与区域相连的网格,因此研究区域包括53个网格,网格内填充黄色。
需求数据集分为70%的训练集,由5月1日至6月11日的观测数据组成;10%的验证集,由6月12日至6月17日的观测数据组成;20%的测试集,由6月18日至6月30日的观测数据组成。图3显示了在训练期(红虚线前)、验证期(红虚线与绿虚线之间)和测试期(绿虚线后)不同天内所有研究区域的总需求。
图4展示了训练集数据一天中不同时段共享单车需求的均值和方差,可以看出,工作日和休息日的共享单车需求均呈现双峰性质。但工作日的双峰更陡,工作日的峰值高于休息日的峰值。可以观察到,休息日的需求较低,这对短期需求预测提出了挑战。
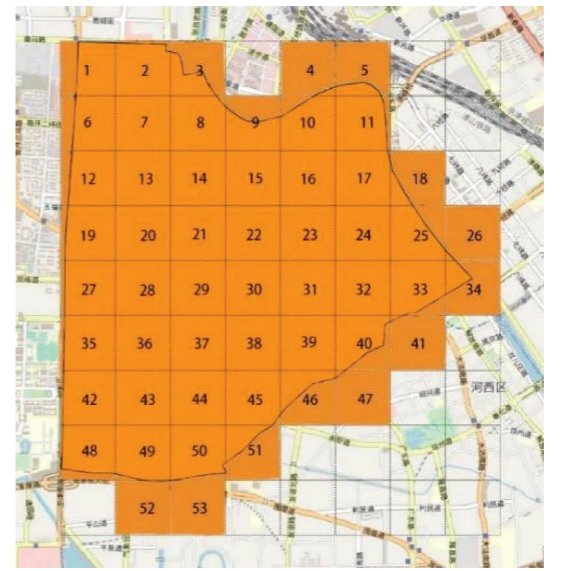
图2 调查区域(用数字标记)

图3 所有网格在不同天的总需求

图4 每天不同时段共享单车需求的均值和方差
为了验证时空变量是否存在时空相关性,本文使用Pearson相关系数来检验第t个时间间隔的需求与第t个时间间隔之前的时空变量之间的相关性,计算公式为:

其中X和Y是两个观测次数相同的随机变量。
首先,对所有![]() 计算了网格(m, n)中t时刻的需求与网格(m', n')中t−k时刻的需求之间的Pearson相关系数。对于所有的
计算了网格(m, n)中t时刻的需求与网格(m', n')中t−k时刻的需求之间的Pearson相关系数。对于所有的![]() .其次,这篇论文的平均水平按距离和回顾时间间隔划分的相关系数。网格(m, n)和(m', n')的距离表示为两个网格中心点之间的欧氏距离。
.其次,这篇论文的平均水平按距离和回顾时间间隔划分的相关系数。网格(m, n)和(m', n')的距离表示为两个网格中心点之间的欧氏距离。
图5展示了因变量(网格(m, n)在t时刻的需求)和解释变量(网格(m', n')在t−k时刻的需求)的平均相关系数。从图中可以看出,随着距离的增加,平均相关系数逐渐减小,证明了各区域与相邻区域之间存在空间相关性。另一方面,回顾时间间隔越小,变量的相关性越强。Pearson相关系数证实时空变量具有时空相关性。
4.2 建成环境变量
4.2.1 土地用途类型
本文通过Python获取百度地图的的POI数据,包括经度、纬度、名称、地址和行政区域。包括地铁站、公园、购物中心、培训机构、办公楼、学校、知名企业、住宅小区、综合餐厅等九大类POI。
4.2.2 公共交通可达性
本文从百度地图收集了公共交通数据,并调查了有多少种公共交通方式(地铁和公交车)将一个地区与另一个地区连接起来。
4.3 天气变量
本文还收集了中国气象局提供的同期一小时的综合天气变量,包括气温、天气状态、风速和空气质量指数。本文还收集了一些变量,包括工作日、周末和节假日。

图5 Pearson相关系数
4.4 预测结果
具有完整变量的SGCNPM分别在训练集上进行训练,在测试集上进行验证。聚集矩阵![]() 选择K等于2的切比雪夫多项式函数。模型分为五层:一层输入层、三层隐藏层和一层输出层。每个隐藏层有8个隐藏单元。为了解决过拟合问题,本文引入L2参数正则化。模型使用ReLU作为图卷积网络的激活函数。本文预测了一天24小时的需求,输出是一个24×53的矩阵。本文预先分析了轮次、时间步长、批量大小对结果的影响,如图6所示。然后,将轮次、时间步长和批量大小分别设置为100、12和24,因为这三个值有最好的预测结果。本文中有53个区域,每个节点代表一个地图区域,所以本文将节点设为53。
选择K等于2的切比雪夫多项式函数。模型分为五层:一层输入层、三层隐藏层和一层输出层。每个隐藏层有8个隐藏单元。为了解决过拟合问题,本文引入L2参数正则化。模型使用ReLU作为图卷积网络的激活函数。本文预测了一天24小时的需求,输出是一个24×53的矩阵。本文预先分析了轮次、时间步长、批量大小对结果的影响,如图6所示。然后,将轮次、时间步长和批量大小分别设置为100、12和24,因为这三个值有最好的预测结果。本文中有53个区域,每个节点代表一个地图区域,所以本文将节点设为53。
模型通过四种有效性指标进行评估:平均绝对误差(mean absolute error,MAE)、平均绝对百分比误差(mean absolute percentage error, MAPE)、均方根误差(root mean squared error,RMSE)和决定系数(R2),计算公式为:
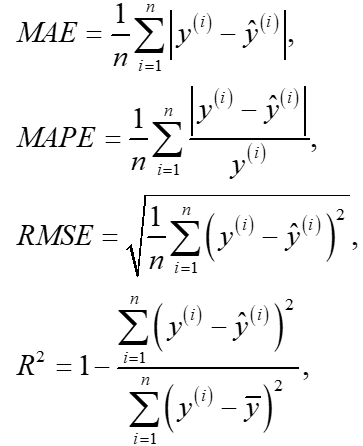
其中![]() 和
和![]() 分别为第i个真实值和需求预测值,
分别为第i个真实值和需求预测值,![]() 为
为![]() 的均值,n为测试集的大小。本文采用MAE、RMSE和R2来衡量整个试验数据的总体预测精度,采用MAPE来衡量模型在高需求区域和高需求时段的预测性能。
的均值,n为测试集的大小。本文采用MAE、RMSE和R2来衡量整个试验数据的总体预测精度,采用MAPE来衡量模型在高需求区域和高需求时段的预测性能。
为了研究融合权重,对不同权重下的结果进行了分析,并对53个地区的共享单车需求进行了预测。如图7所示,当![]() 时,模型的预测效果最好。
时,模型的预测效果最好。
文章运用SGCNPM对53个地区的共享单车需求进行预测,结果如图8和表2所示,发现地区7的预测效果最好,地区8的预测效果最差。图8显示了各区域的MAE,区域7最小,区域8最大。表2显示了各区域预测结果的平均值,MAE、MAPE、RMSE和R2分别为8.209、37.12%、11.527和0.737。
图9显示了误差热力图,其中颜色更深、更密集的点代表更大的需求。从热力图中可以看出,高峰时段(如上午8-9点和下午6-7点)的误差比上午0-1点和晚上11-12点时间段要高得多,热力图能准确反映误差。结合短期需求预测和可视化分析,可以帮助运营商快速识别误差较大的区域并进行调整。
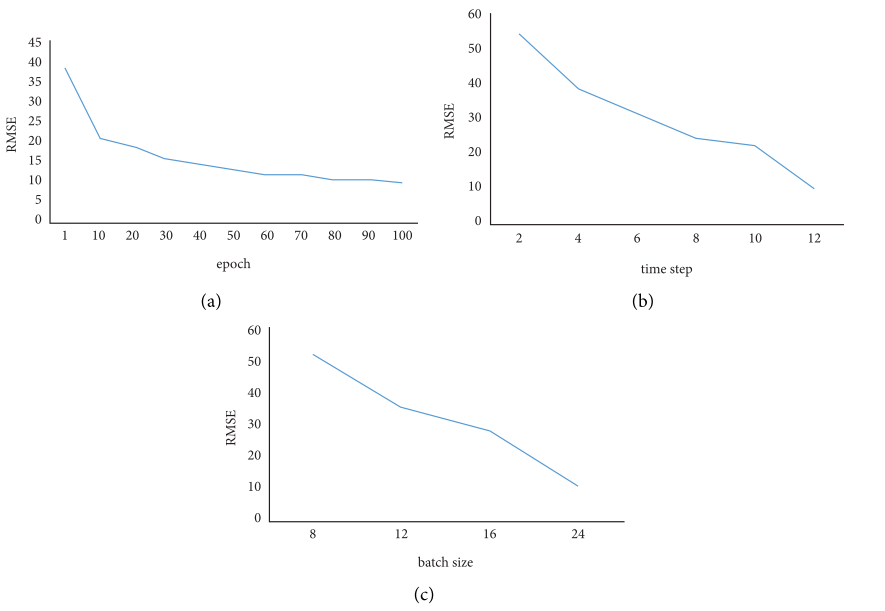
图6 (a)轮次 (b)时间步长 (c)批量大小
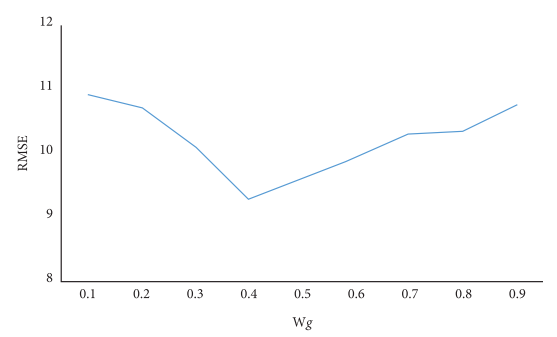
图7 不同权重下的预测结果
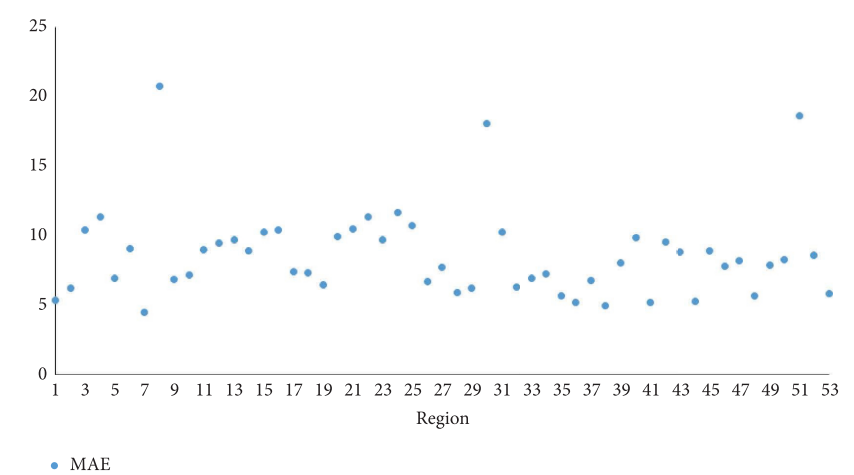
图8 每个地区的MAE
表2 区域7和区域8的预测结果

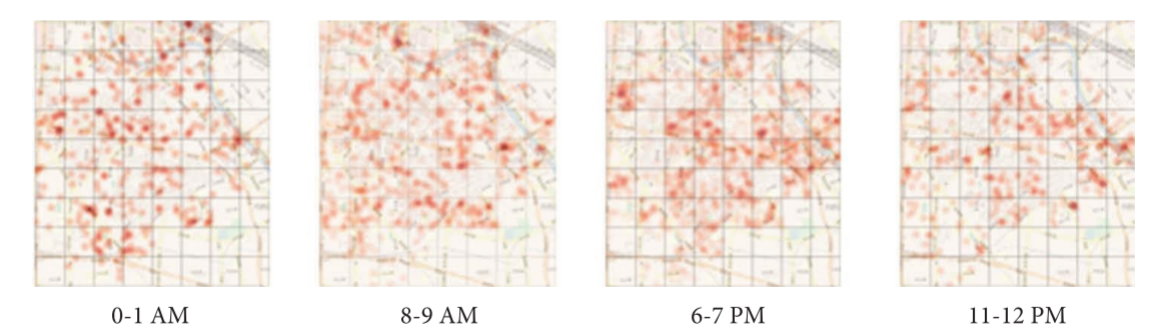
图9 误差热力图
4.5 模型比较
4.5.1 与其他模型的比较
除了提出的模型外,还对其他算法进行了测试。算法包括4种传统的时间序列预测模型(HA、MA、ARIMA和Holt指数平滑)和几种学习/深度学习方法(ANN、LSTM和GRU)。
(1)HA:历史平均模型基于训练集中的经验统计量预测测试集中未来的需求。例如,网格(m, n)中上午7-8点期间的平均需求是根据网格(m, n)中上午7-8点期间的所有历史需求估算出来的。
(2)MA:移动平均模型在时间序列分析中被广泛应用。它通过最近一些历史需求的平均值来预测未来的需求。本文利用网络(m, n)中12 个历史需求的平均值来预测网络未来需求。
(3)ARIMA:自回归综合移动平均模型综合了自回归(AR)、整合(I)和移动平均(MA)三个部分,考虑了数据集的趋势、周期性和非平稳特征。
(4)Holt指数平滑:Holt指数平滑模型在简单指数平滑系数α的基础上增加趋势平滑系数β,又称双参数平滑方法。
(5)ANN:人工神经网络使用特定网格(m, n)的所有变量,包括历史需求、出行时间率、小时状态、周状态和带回溯时间窗的天气变量,来预测网格(m, n)上的未来需求。神经网络不能区分不同时间的变量,因此不能捕捉时间相关性。
(6)LSTM:在LSTM中,将网格(m, n)中的所有变量重构为一个矩阵,其中一个轴为时间步长(其大小等于回溯时间窗k=12),另一个轴是特征类别。这样,SGCNPM中使用的所有特征都被发送到LSTM进行训练。LSTM考虑时间相关性,但不考虑空间相关性。
(7)GRU:门控循环单元是一种神经网络,其性能与LSTM相似,但计算成本较低。
上述深度学习方法与SGCNPM具有相同的输入特征(相同的类别和回溯时间窗口),4个时间序列模型(HA、MA、ARIMA和Holt指数平滑)使用的是相同的时间序列。此外,深度学习模型(ANN、LSTM和GRU)也进行了100轮的训练。在模型训练和验证之前,所有的数据通过相同的标准化方法,归一到[0,1]范围内。
研究使用Python 3.7和TensorFlow 1.14.0、Keras和scikit-learn来比较模型。
对于所有的方法,本文都对验证集进行了预测。表3比较了20次运行中不同预测方法的结果。本文在结果中观察到以下现象。(1)ANN、LSTM、GRU和SGCNPM等深度学习方法的预测结果优于其他模型。(2)在同一数据集上,SGCNPM在所有指标上都取得了最好的结果。(3)度学习方法比其他方法耗时更长,其中SGCNPM耗时最长。(4)各种方法获得的MAPE均较大。
4.5.2考虑不同因素的SGCNPM
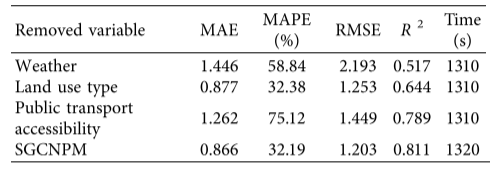
为了验证考虑多因素的必要性,本文对SGCNPM进行了重构,分别去除天气变量、土地利用类型变量和公共交通可达性变量,预测结果如表4所示。剔除公共交通可达性变量后,预测精度下降幅度最大,MAE从8.209提高到11.223,RMSE从11.527提高到14.017。如表4所示,删除任何一个变量都会导致预测误差的增加,这反映了每个变量的重要性。
此外,为了分析SGCNPM在不同时段的准确性,本文分别对白天和晚上的共享单车需求进行了预测。对模型重新校准。结果如表5和表6所示。本文提出了几点结论。
有必要考虑所有的变量。考虑所有变量的预测结果在白天或夜间都是最好的。白天MAE、MAPE、RMSE和R2指标分别为8.377、20.21%、10.648和0.738;夜间MAE、MAPE、RMSE、R2指标分别为0.866、32.19%、1.203、0.811,夜间的MAE和RMSE指标小于白天,而MAPE指标大于白天,因为白天的共享单车需求大于夜间。
表3 不同自行车共享需求预测模型的结果比较
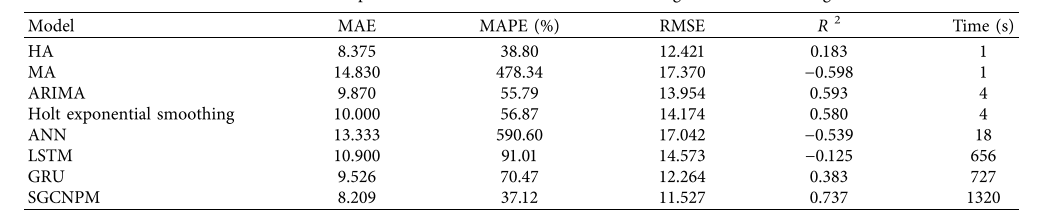
表4 删除任何变量的结果比较

表5 删除任何变量的结果比较(删除23:00-6:00期间的数据后)

表6 删除任何变量的结果比较(删除6:00-23:00的数据后)
5. 结论
本文首先对天津市和平区共享单车出行行为进行了分析。SGCNPM预测各区域的共享单车需求,为共享单车调度提供技术支持。SGCNPM是建成环境变量模型和天气环境变量模型的融合。建成环境变量模型集成了距离图、POI图和互连图。天气环境变量模型考虑了天气状态、最高温度、最低温度、风速和空气质量指数的影响。模型能较好地反映时空相关性、建成环境和天气对共享单车需求的影响。通过对比预测结果,发现SGCNPM的预测精度优于HA、MA、ARIMA、Holt指数平滑、ANN、LSTM和GRU。此外,本文还发现,当模型中缺失建成环境变量或天气变量时,无论在那个时段进行预测,预测精度都会下降。由此可见,构建的环境变量和天气变量是预测共享单车需求的关键。未来的研究将深入分析基于共享单车需求预测的共享单车分配与调度问题,并不断完善模型。