基于强化学习的自动驾驶车辆路上突发障碍物换道避障控制算法
基于强化学习的自动驾驶车辆路上突发障碍物换道避障控制算法
作者:姚恩建,陈卓利,郝 赫,陈荣升,杨 扬
论文期刊:北京交通大学学报
论文网页:https://jdxb.bjtu.edu.cn/CN/10.11860/j.issn.1673-0291.20250149。
摘要
针对高速公路突发障碍物情景下自动驾驶车辆的换道避障问题,本文提出了一种基于深度强化学习(Deep Reinforcement Learning,DRL)的车辆控制方法。首先,将该问题视为马尔可夫决策过程,融合局部环境观测、车道语义信息与自车全局状态,构建结构化的混合状态空间,以增强对复杂交通环境与潜在风险的感知能力。动作空间采用连续形式的前轮转向角与纵向加速度,实现精细化车辆控制;奖励函数以二维预碰撞时间(Two-dimensional Time-to-Collision,2D-TTC)为核心指标,同时引入安全性、效率、舒适性与交通规则等奖励,并通过条件化动态权重机制,使策略在高风险场景下优先保障安全,在低风险场景下提高通行效率。其次,通过引入延迟策略更新与目标策略平滑机制,有效缓解深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法在训练过程中易出现的训练不稳定性 Q 值过估计问题。最后,在多种典型交通场景下开展仿真验证结果表明,所提出方法与多种基准算法相比,在安全性与效率方面均表现出显著优势:在训练阶段,首次与连续避障成功率最高分别提升约 17.9% 和 60.5%,安全性指标最高提升约 7.6%,平均速度最高提升约 2.1%;在各种测试场景中,首次与连续避障成功率最高分别提升约 25.9% 和 44.1%,安全性指标最高提升约 9.8%,平均速度最高提升约 0.6%。
关键词:自动驾驶车辆;路上突发障碍物;深度强化学习;2D-TTC;换道避障控制
1 研究背景与意义
自动驾驶技术的快速发展为解决交通安全、道路拥堵和能源消耗等重大问题带来了新的机遇,智能网联汽车的普及被认为能够有效减少因驾驶员失误导致的事故,并提升道路运行效率。然而,自动驾驶车辆在复杂的真实交通环境中仍然面临诸多挑战,包括环境感知的准确性、行为决策的可靠性以及人车交互中的不确定性。其中,高速公路上出现突发障碍物的场景尤为关键,若自动驾驶车辆无法进行及时且合理的避让,不仅可能直接引发交通事故,还可能导致交通流紊乱和拥堵,严重影响行车安全与道路通行效率。尽管现有的主动避障研究,如基于神经网络采样、遗传算法或最优控制的轨迹规划方法取得了显著进展,但多数方法在应对高动态、强交互的混合交通场景时,仍存在实时性、泛化性不足以及对安全约束考虑不充分的问题。近年来兴起的深度强化学习方法虽能实现端到端的控制,但其训练过程往往不稳定,且策略在面临突发高风险状况时难以保证安全性与鲁棒性。
在此背景下,本研究针对路上突发障碍物场景下自动驾驶车辆的换道避障控制问题,提出了名为SafeLC-DelayDDPG的算法,具有重要的理论创新价值和实际应用意义。在理论层面,该研究通过将问题建模为马尔可夫决策过程,构建了一个结构化的混合状态空间,创新性地融合了局部观测、车道语义信息和自车全局状态,从而显著提升了智能体对环境的感知能力与风险敏感性。其奖励函数以二维碰撞时间(2D-TTC)指标为核心,并采用了条件化动态权重机制,使学习策略能在高风险时优先保证安全,在低风险时兼顾行驶效率。此外,算法通过引入延迟策略更新和目标策略平滑等机制,有效缓解了原有DDPG算法训练不稳定和Q值过估计的缺陷,提升了算法的整体性能。
2 问题描述与建模
2.1问题描述
将自车(ego vehicle)在路上突发障碍物情境中的安全换道避障问题建模为马尔可夫决策过程(Markov Decision Process, MDP)。在本场景的整个驾驶过程中,智能体(自动驾驶车辆)以离散时间步与环境交互:在时刻t,基于当前状态选择并执行动作,环境据此反馈即时奖励并转移至下一状态 ;智能体利用转移四元组持续改进策略,以最大化期望累计回报。该闭环交互与马尔可夫性假设相契合,使得避障换道任务可自然纳入强化学习范式求解。
单一受控的自车设为智能体,其他交通参与者均视为环境组成,并以传统模型模拟其驾驶行为,从而在保证环境可复现与可控的前提下,突出对单智能体策略的学习与评估。基于此设定,对状态空间、动作空间与奖励函数建模进行介绍。
2.2状态空间
2.2.1局部稠密特征公式
算法通过公式 (1)构 建局部观测的稠密表示:

技术意义:该公式实现了环境信息的结构化编码,为神经网络提供标准化的输入特征,显著提升了感知效率和解耦能力。
2.2.2安全指标:2D-TTC计算公式
算法的安全度量指标由公式 (2) 定义:

技术意义:与传统TTC相比,2D-TTC在二维空间内计算碰撞风险,更符合实际驾驶场景的几何关系。
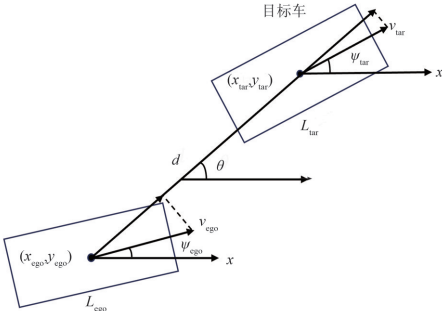
图1:2D-TTC计算公式图解
2.3 奖励函数
2.3.1安全性奖励的分段函数设计
公式(4)定义了基于TTC值的分段奖励机制:

系数优化:通过、等参数的精心调整,实现了风险响应灵敏度与稳定性的平衡。
2.3.2 效率奖励的线性组合
公式(12)-(14)构建了效率奖励体系:
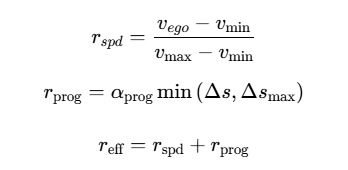
设计理念:速度奖励促进高效通行,进度奖励鼓励向前运动,两者结合确保在安全前提下提升通行效率。
2.4 动作空间与运动学模型
2.4.1 动作到物理指令的映射
公式(19)-(20)实现归一化动作到物理量的转换:
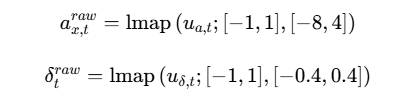
映射函数:lmap为线性映射函数,将神经网络输出的归一化值转换为实际物理量,确保动作在可行范围内。
2.4.2 车辆运动学模型
公式(28)-(38)构建了完整的车辆状态更新体系:
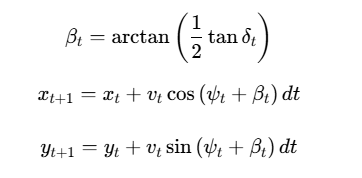
模型特色:基于改进的自行车模型,考虑质心侧偏角的影响,更准确描述车辆动力学行为。
2.5算法优化公式
2.5.1目标策略平滑技术
公式(40)引入策略平滑机制:

2.5.2 Huber损失函数
公式(43)采用平滑损失函数:

优势分析:相比均方误差,Huber损失对异常值不敏感,在保持收敛性的同时增强训练稳定性。
3 仿真验证
3.1 训练效果显著
经过10000回合的训练,SafeLC-DelayDDPG表现出色:避障成功率大幅提升:首次避障成功率82.3%,连续避障成功率72.7%,相比基线算法分别提升约17.9%和60.5%;安全性指标优化:2D-TTC值达到1.84s,提升7.6%;效率保持良好:平均速度19.66m/s,提升2.1%。
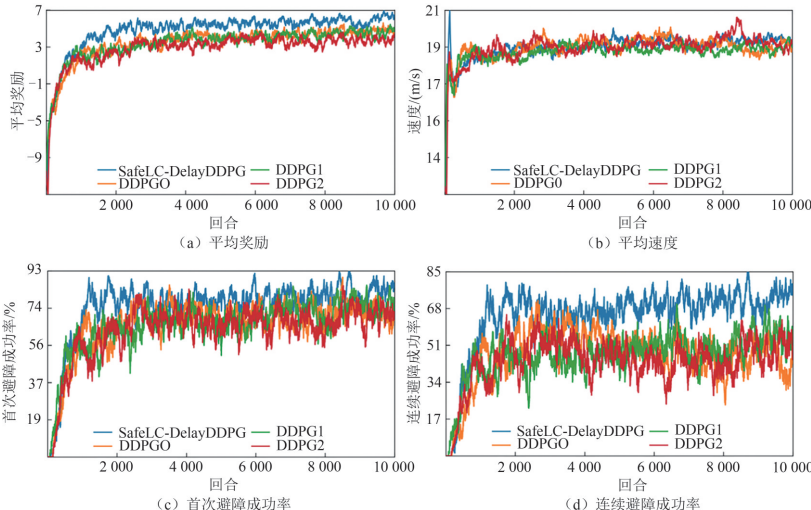
图2:训练期不同算法各指标变化曲线图
3.2 多场景测试表现优异
在36个测试场景中,算法展现出强大的泛化能力:首次避障成功率最高提升25.9%,连续避障成功率最高提升44.1%,安全性指标最多提升9.8%,平均速度保持稳定提升。
典型应用场景展示
研究团队提供了学得策略在典型场景中的行为表现示例。如图所示,自车(黄色车辆)在面对突发障碍时,能够做出平滑、安全的换道避障决策:
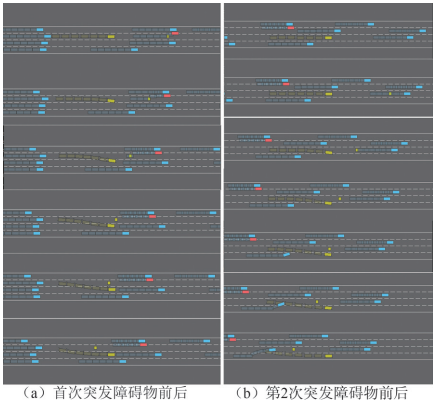
图3: 学得策略在典型场景中的行为快照
避障过程中,自车轨迹平滑连续,速度控制合理,展现出算法在实景中的优异性能:
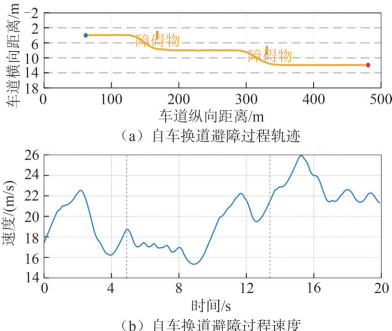
图4:自车典型场景换道避障过程运动曲线图
1)相较于基线算法,SafeLC-DelayDDPG算法能够在训练阶段最多提高首次避障成功率17.9%、连续避障成功率60.5%,证明了提出算法能够显著提升自车在复杂交通场景下的感知与决策能力,通过将局部观测、车道语义信息和自车全局状态有效融合的状态空间设计有效增强了环境感知与风险敏感性,在提升任务完成度和避障效率方面具备有效性。
2)相比基线算法,SafeLC-DelayDDPG算法训练阶段在安全性(2D-TTC)指标上提高了最多7.6%,平均速度提升最多2.1%,表明该算法通过引入2D-TTC为核心的奖励函数设计,成功地平衡了安全性与效率。特别是在高风险场景下,采用了条件化动态权重机制,有效使策略能优先保证安全,低风险时提升效率。
3)在36个测试场景中,相比基线算法,SafeLC-DelayDDPG首次避障成功率最高提升了25.9%,连续避障成功率最高提升44.1%,安全性指标值最多提升约9.8%,平均速度最多提升约0.6%,证明了算法在多场景复杂动态环境下具备适应性及高效性,在不同交通流形态与障碍物生成TTC设定下表现出了较强的鲁棒性和泛化能力,在训练未见过的场景中,算法依然能够保持较高的任务完成度。
后续研究可围绕不确定性与环境真实性展开。在AC连续控制框架下,可考虑显式刻画不确定性:一方面通过模型集成的方法表征认知不确定性,另一方面以概率输出或混合密度网络描述固有不确定性,并探索分布式/风险敏感强化学习对稳健性的潜在提升;考虑针对更复杂的突发动态障碍(急加减速、急转向、并线插入等)以增加任务难度;为增强仿真的外部有效性,还可基于真实数据集重建背景车流分布以贴近实测驾驶风格;在以上仿真设置的基础上引入感知噪声、执行器饱和与系统时延等工程因素,进行消融与鲁棒性评测。